7.16 开始项目 7.28 更新requests基础 7.29 更新了百度翻译和豆瓣电影的项目
1.背景介绍
刚好到了志愿填报季,报志愿也是考生和家长都比较关心的问题。现在一切都从工程的角度看问题,做出来的项目必须是有实际意义的东西,不能只做成半成品或者仅仅验证算法,那样的话就没有多少意义。 高考志愿填报是一个大部分人都比较熟悉的东西,只不过现在比以往会复杂一些,多了很多各种各样的计划,提前批那样的情况。现在也有很多机构和网站都在做类似的东西,换句话说,他们掌握的信息和算法不见得有个人掌握的多,因此,这是一个没有太多知识壁垒的项目。也是为后续做类似的应用做基础和准备。 Github链接 https://github.com/DuLiCS/CEE_crawler
2.大体思路
这个项目对于基于数据的项目来说,是比较典型的,因此第一步是数据的获取,简而言之,就是要使用到爬虫技术。因此这篇文章作为Part I,主要就是阐述如何设计,获取数据,最后成为数据库可以随时存取使用。
3.爬虫基础
爬虫的选取涉及两个问题,使用什么工具和语言,因为是爬虫的第一个项目,我想还是选择熟悉的语言,所以还是用Python来写,selenium我之前用过,但是速度还是慢了点。我想用一下其他包试试看,talk is cheap,直接写吧。
3.1 Requests 模块
Requests is an elegant and simple HTTP library for Python, built for human beings.

3.1 基础
- 安装
To install Requests, simply run this simple command
$ pip install requests
- Make a Requets
Begin by importing the Requests module:
>>> import requests
Get a webpage
url = 'https://www.sougou.com'
response = requests.get(url)
page_text = response.text
with open('./sogou.html', 'w', encoding='utf-8') as fp:
fp.write(page_text)
这样就把搜狗首页放在了sogou.html文件中。接下来如果想得到搜索的结果,比如搜索高考,那就需要访问这样带参数的网址 ‘https://www.sogou.com/web?query=高考’,在处理这样的请求时,可以把问号后的参数进行传递,于是有了下面的代码:
url = 'https://www.sogou.com/web'
keyword = '高考'
param = {
'query': keyword
}
response = requests.get(url, params=param)
page_text = response.text
fileName = keyword + '.html'
with open(fileName, 'w', encoding='utf-8') as fp:
fp.write(page_text)
最终得到的结果是这样的:

当我们用浏览器访问的时候发现网站其实是可以响应的。这个请求被认为不正常,因此被拦截。 我们也可以试试gaokao.com的情况,发现也是类似。
因此在这里需要使用UA(User Agent)伪装成正常的浏览器,在这里首先查一下我用的safari浏览器的UA,chrome也是类似的。在网页点击右键,选择检查元素。在网络选项卡中找到,将UA的值复制下来,传入get方法的headers参数中。
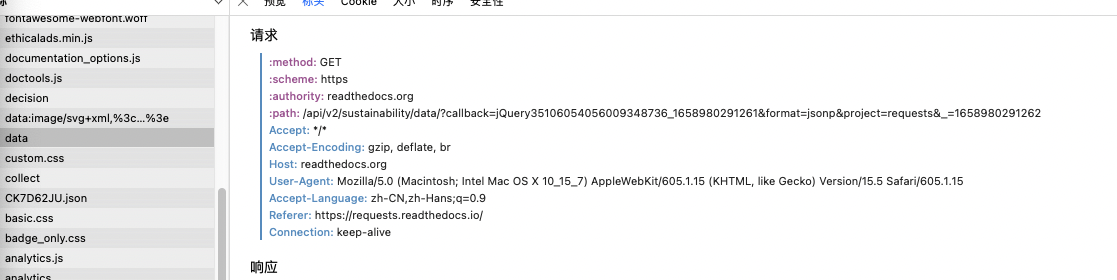
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) '
'Version/15.5 Safari/605.1.15 '
}
url = 'https://www.sogou.com/web'
keyword = '高考'
param = {
'query': keyword
}
response = requests.get(url, params=param,headers=headers)
page_text = response.text
fileName = keyword + '.html'
with open(fileName, 'w', encoding='utf-8') as fp:
fp.write(page_text)
这时候再看页面,已经正常了。
3.2 案例一 百度翻译
使用翻译时,会出现页面局部刷新的情况,此时需要获取局部刷新的结果。此时可以在开发者模式中寻找相应的抓包工具。
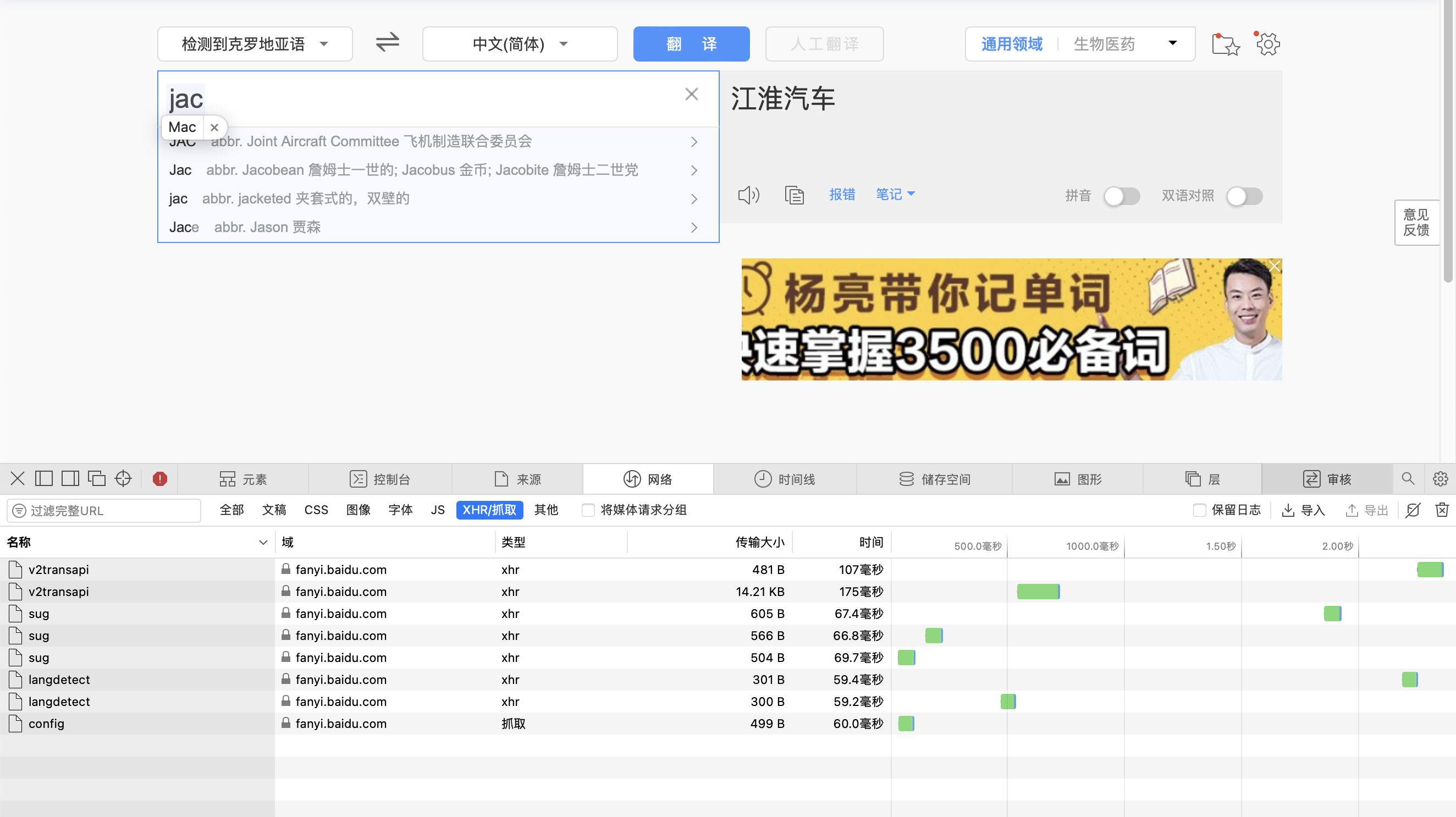
挨个分析查找对应的包。
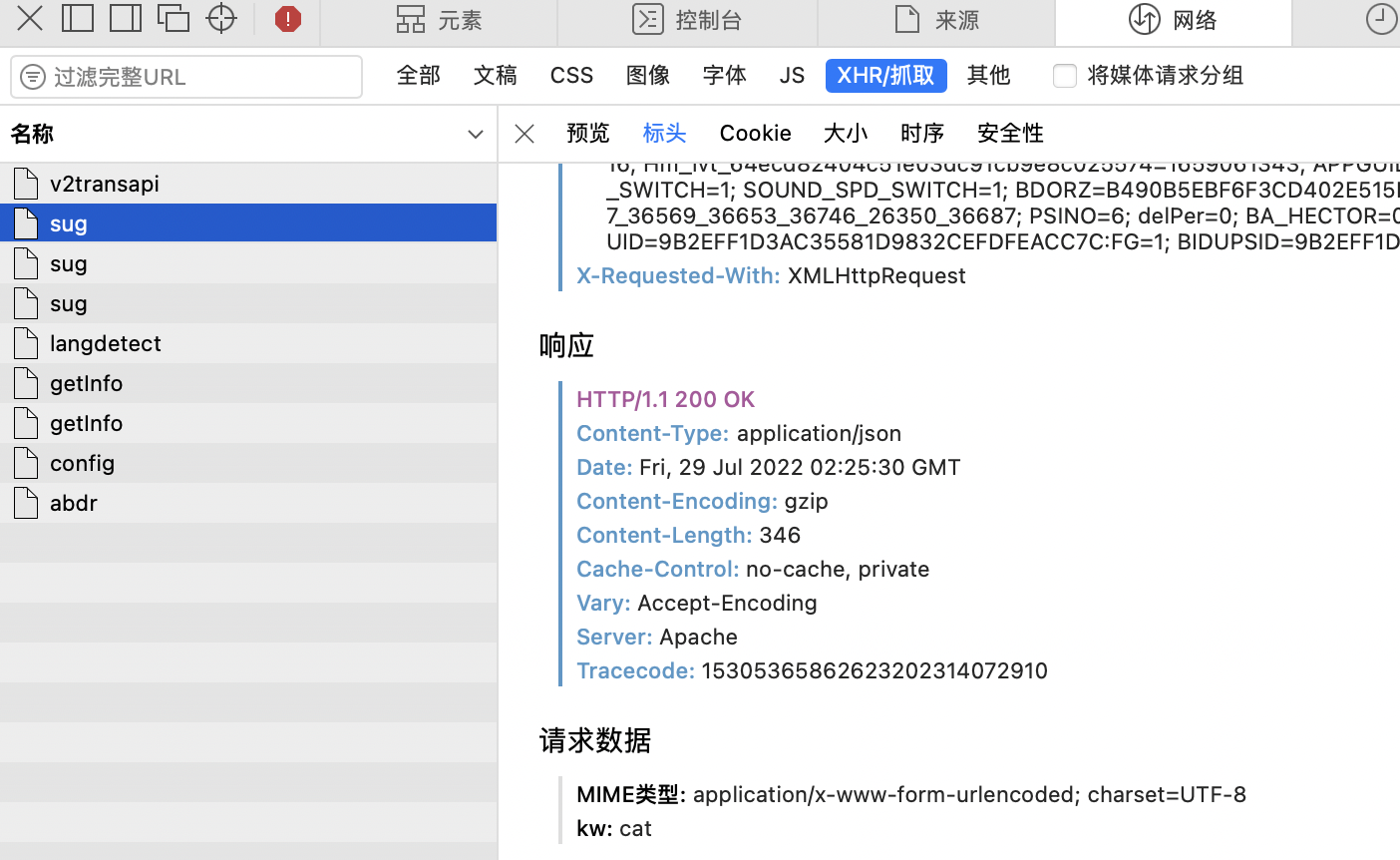
查看内容。
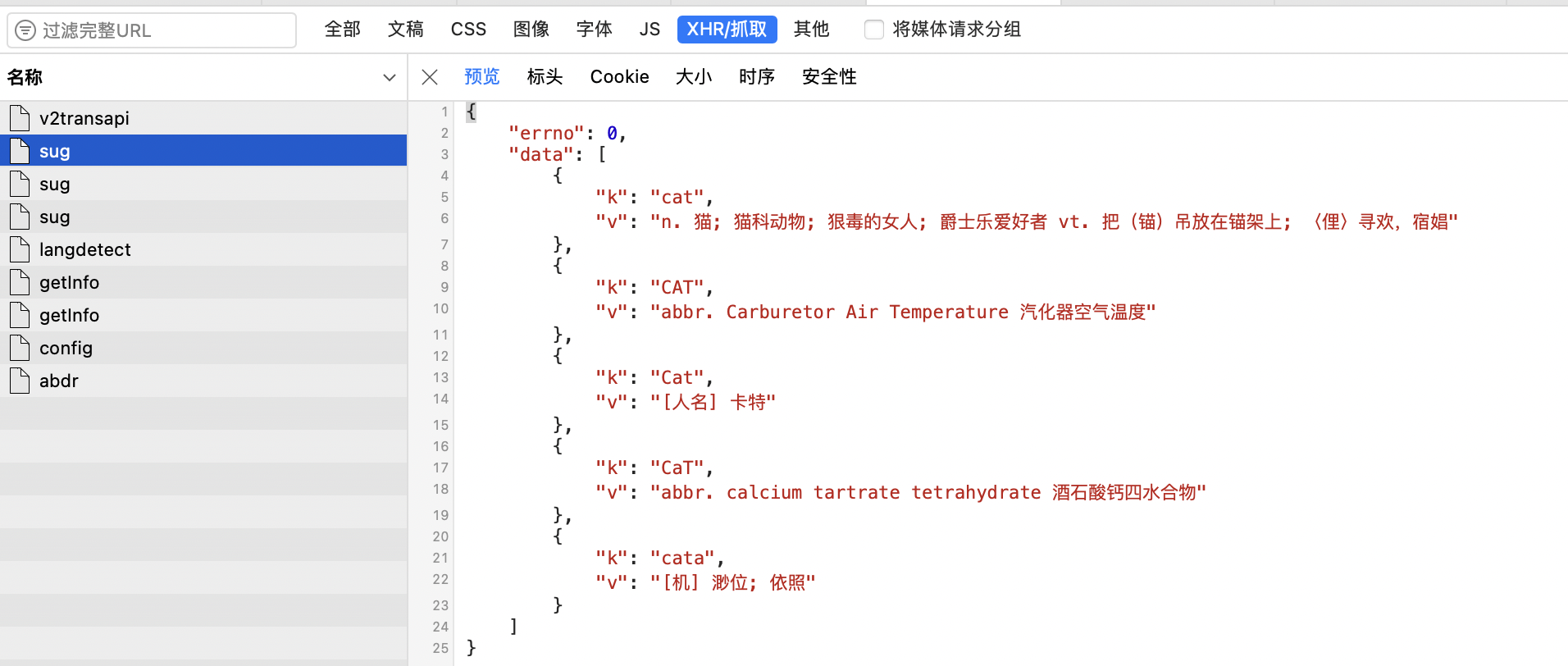
Code:
import requests
import json
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) '
'Version/15.5 Safari/605.1.15 '
}
post_url = 'https://fanyi.baidu.com/sug'
data = {
'kw': 'cat'
}
response = requests.post(post_url, data, headers=headers)
dic_obj = response.json()
fp = open('./cat.json', 'w', encoding='utf-8')
json.dump(dic_obj, fp=fp, ensure_ascii=False)
3.3 豆瓣电影排行榜
这里是要将豆瓣电影的某个分类下的排行榜的数据爬取出来,例如这个链接下的纪录片排行。https://movie.douban.com/typerank?type_name=纪录片&type=1&interval_id=100:90&action= 我们在滚动页面的时候,会展示更多的页面,这也是一个抓包的问题,因此捕获一下。
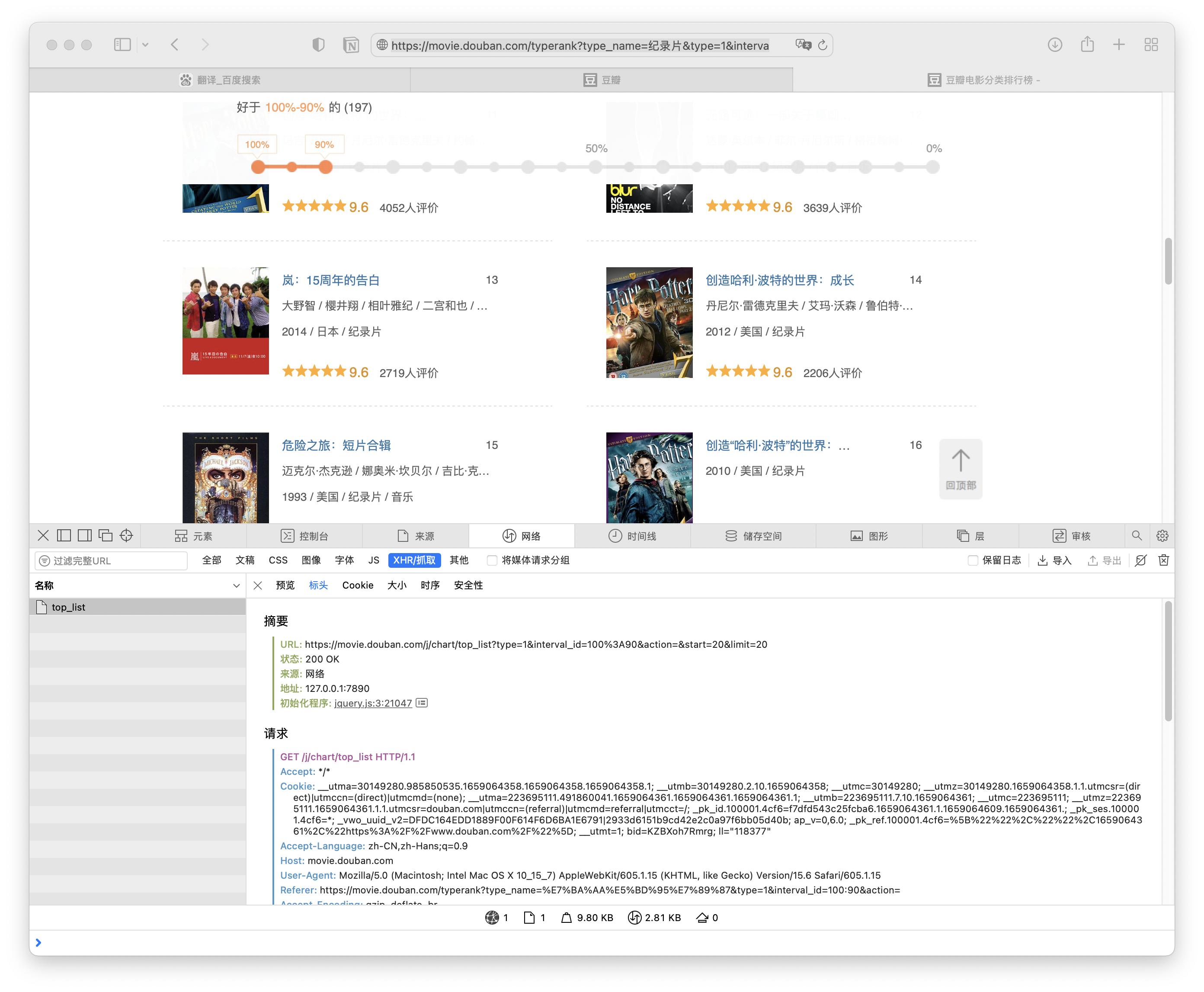
代码和上一个项目类似。 Code:
import requests
import json
url = 'https://movie.douban.com/j/chart/top_list'
params = {
'type': '1',
'interval_id': '100:90',
'action': '',
'start': '1',
'limit': '20'
}
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) '
'Version/15.5 Safari/605.1.15 '
}
response = requests.get(url, params=params, headers=headers)
list_data = response.json()
fp = open('./douban.json', 'w', encoding='utf-8')
json.dump(list_data, fp, ensure_ascii=False)
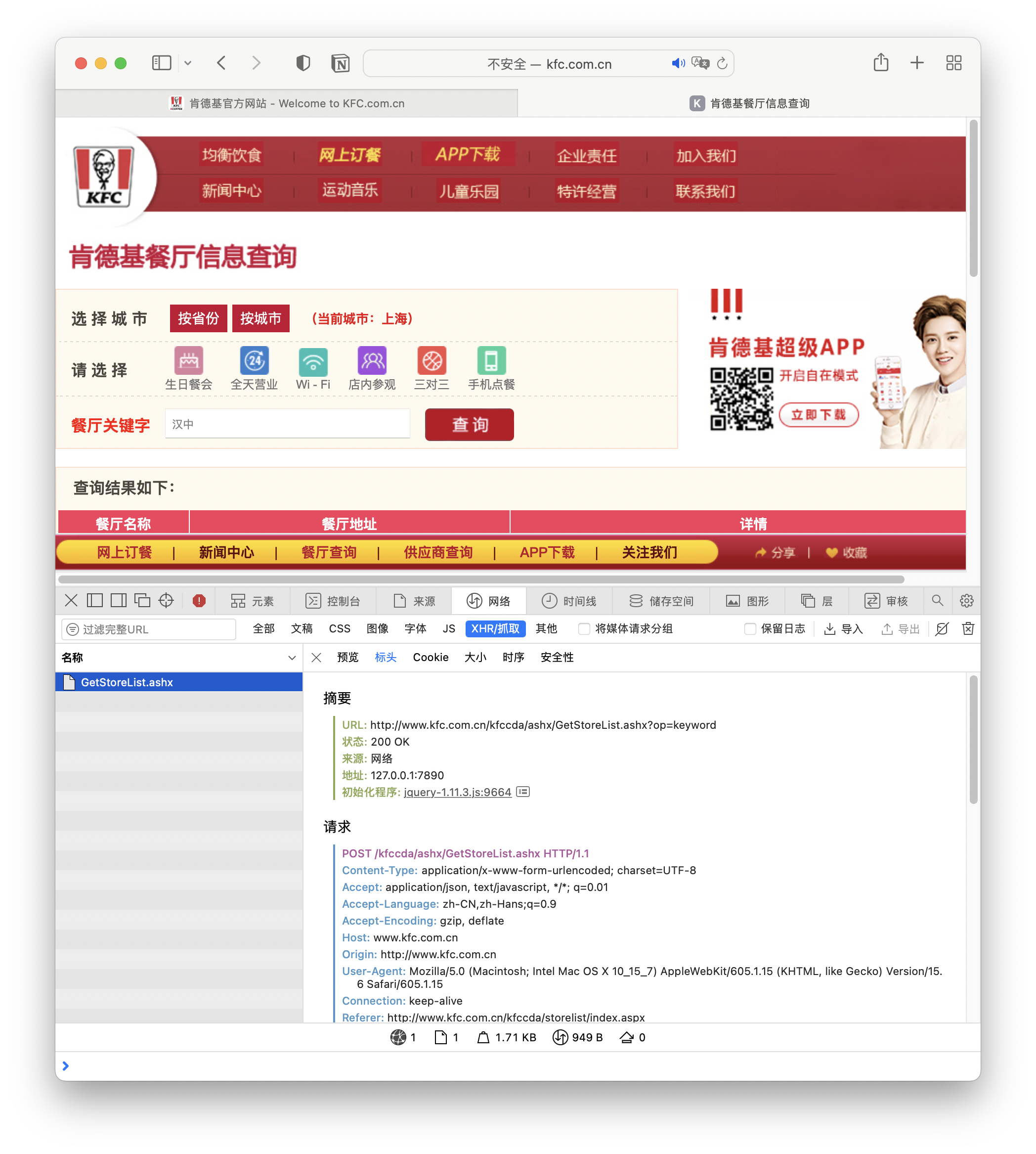
3.4 肯德基餐厅查询
和上面的方法也是类似的,打开网页,点击查询找XHR内容。餐厅查询网址 http://www.kfc.com.cn/kfccda/storelist/index.aspx。
7.16 更新1 7.28 更新2 7.29 更新了百度翻译和豆瓣电影的项目