1.4 Data Labeling
1.4.1 Semi-Supervised Learning(SSL)
- Focus on the scenario where there is a small amount of labeled data,along with a large amount of unlabeled data.
- Make assumptions on data distribution to use unlabeled data
- Continuity assumption
- Cluster assumption
- Manifold assumption
- Self-training
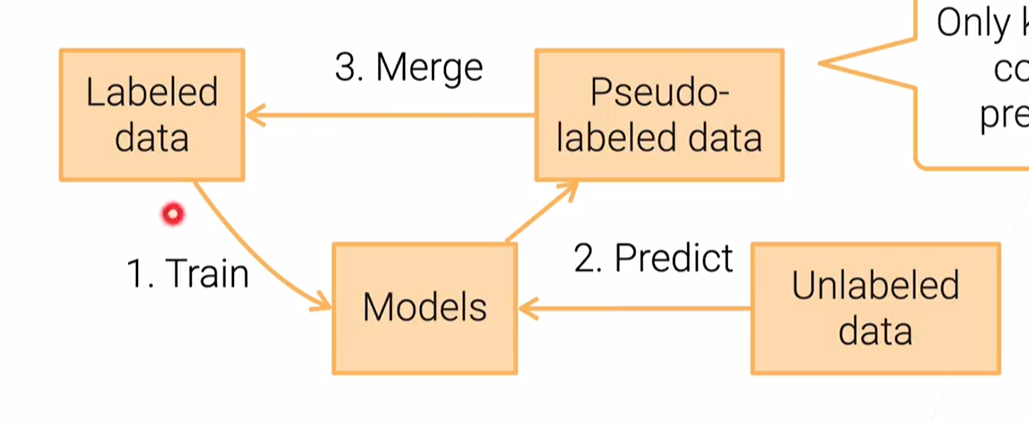
- We can use expensive models like deep neural network,model ensemble/bagging
1.4.2 Label through Crowsourcing
- Challenges
- Simplify user interaction
- Qulity control
- Cost
1.4.3 Active Learning + Self-training
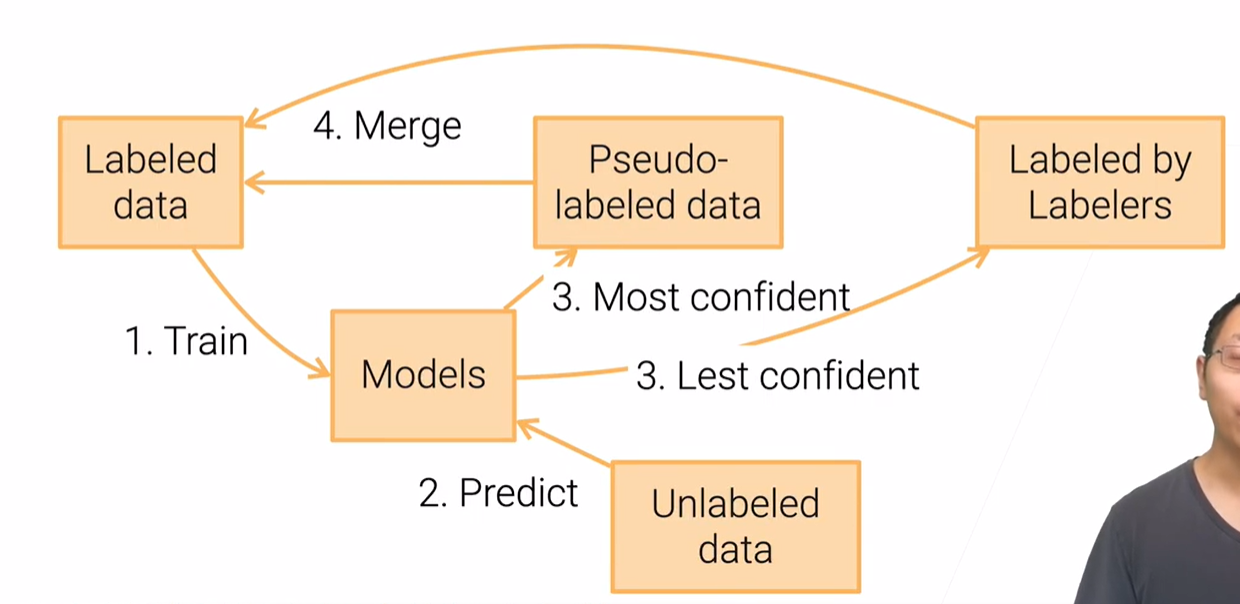
1.4.4 Quality Control
1.4.5 Weak Supervision
- Semi-automatically generate labels
- Less accurate than manual ones,but good enough for training
- Data programming