Research on Topic Network Structure Evolution Recognition of Heterogeneous Online Social Network
异源在线社会网络信息扩散结构演化识别研究
本项目源起于Spence Zhou的硕士毕业论文,需要重新发文章,之前他的代码已经遗失,现在需要重新写,但是他没有时间去做这些事情,因此就交给了我.写这篇post的初衷在于记录整个代码编写的过程.
由于是实现,我们直接从系统设计开始.
1.系统设计
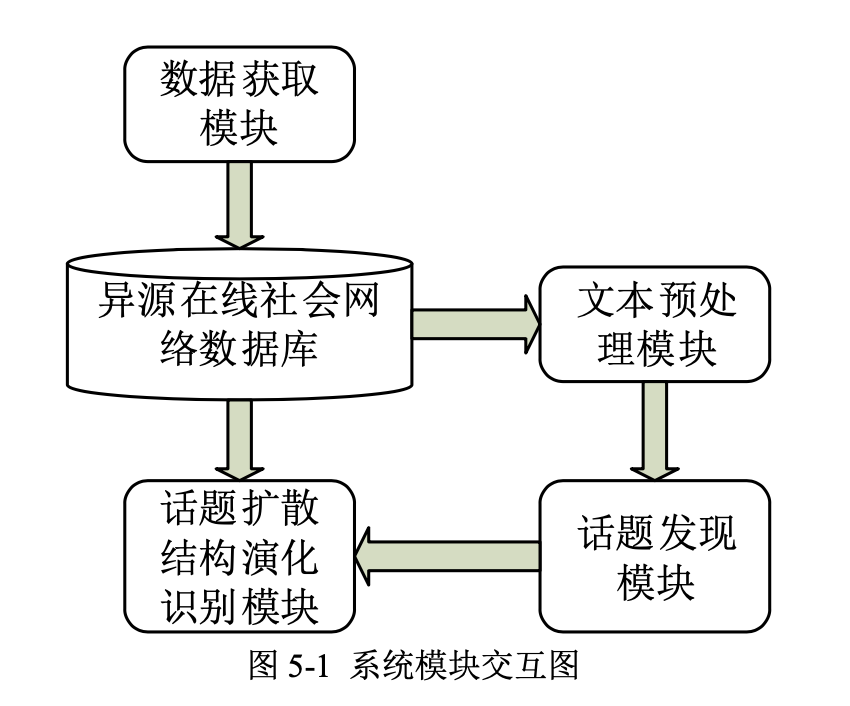
异源在线社会网络话题发现和信息扩散结构演化识别系统包括:数据获取模块、文本预处理模块、话题发现模块、话题扩散结构演化识别模块 4 个模块,系统各模块之间交互关系如图 5-1 所示,数据获取模块将异源在线社会网络中的数据抓取并保存 到系统数据库中,通过文本预处理模块将数据库中的文本信息进行关键词抽取,将处 理后的数据利用文本间基于关键词重合的网络模型构造文本关系网络,对文本关系网 络运用动态社团发现算法进行社团划分从而进行话题发现,将所发现话题的参与用户 信息映射到话题传播网络模型中,再次利用动态社团发现算法对话题传播网络进行动 态社团划分,最对话题扩散结构演化进行识别。本节对系统各个模块的内部流程和详 细设计进行说明。
1.1 数据获取模块设计
数据获取模块是系统的数据来源,通过构建分布式网络爬虫实现对在线社会网络 中的数据进行抓取。分布式爬虫模块包括爬虫监控(Master)、爬虫工作组(Worker Group)、爬虫队列和数据库。 爬虫监控负责分布式爬虫的监控,通过和爬虫工作者(Worker)、队列和数据库进 行通信获取爬虫的运行状况。 爬虫队列存放爬虫待抓取和已抓取的 URL 集合,是网络爬虫的调度中心,通过共 享爬虫队列即可构建分布式爬虫系统,爬虫队列使用存取速度快且支持数据持久化的 内存数据库 Redis 实现。 数据库对网络爬虫抓取的数据进行存储,针对于异源在线社会网络媒体信息数量 庞大、数据集合间关联关系松散的特点选择适用于海量数据存储的 Nosql 数据库 MongoDB。 爬虫工作者(Worker)包含:下载器(Downloader)、web 页面处理器(Processor) 和数据存储器(Pipeline)。下载器负责从爬虫队列中获取待下载 URL,下载页面并将 下载完成页面提供为页面处理器,页面处理器负责从下载器获取的页面中抽取出所需 要信息,同时从页面中获取待抓取的 URL 并写入到爬虫队列中,数据存储器负责将页 面处理器提取的信息持久化到数据库中。