读取数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import timeit
import random
import time
sheet_1 = pd.read_csv("1.csv",encoding='gb18030')
sheet_2 = pd.read_csv("2.csv",encoding='gb18030')
excel3 = pd.ExcelFile('3.xlsx')
sheet_3 = pd.read_excel(excel3)
excel4 = pd.ExcelFile('4.xlsx')
sheet_4 = pd.read_excel(excel4)
筛选出未完成的订单
unfinished_1 = sheet_1[sheet_1['is_finished']==0]
unfinished_2 = sheet_2[sheet_2['is_finished']==0]
num_of_turnover = sheet_1.shape[0] + sheet_2.shape[0]
num_of_unfinished = unfinished_1.shape[0] + unfinished_2.shape[0]
labels = 'unfinished', 'turnover'
sizes = [num_of_unfinished , num_of_turnover-num_of_unfinished]
explode = (0, 0.3) # only "explode" the 2nd slice (i.e. 'Hogs')
fig1, ax1 = plt.subplots()
ax1.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%',
shadow=True, startangle=90)
ax1.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle.
plt.show()
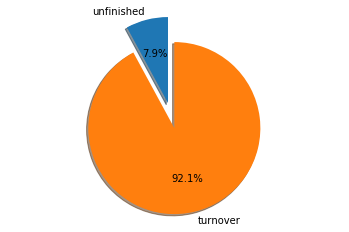
剔除掉7.9%的无效数据
sheet_1 = sheet_1[sheet_1['is_finished']!=0]
sheet_2 = sheet_2[sheet_2['is_finished']!=0]
no_cost_prc_1 = sheet_1[sheet_1['sku_cost_prc'] == 0.0]
no_cost_prc_2 = sheet_2[sheet_2['sku_cost_prc'] == 0.0]
num_of_no_cost_prc = no_cost_prc_1.shape[0] + no_cost_prc_2.shape[0]
64%的记录成本信息缺失
num_of_turnover = sheet_1.shape[0] + sheet_2.shape[0]
labels = 'no cost price', 'turnover'
sizes = [num_of_no_cost_prc , num_of_turnover-num_of_no_cost_prc]
explode = (0, 0.3) # only "explode" the 2nd slice (i.e. 'Hogs')
fig1, ax1 = plt.subplots()
ax1.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%',
shadow=True, startangle=90)
ax1.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle.
plt.show()
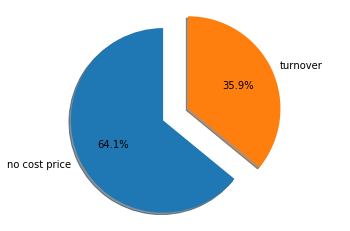
sheet = pd.concat([sheet_1,sheet_2])
no_cost_prc = pd.concat([no_cost_prc_1,no_cost_prc_2])
full_info_turnover = sheet[sheet['sku_cost_prc']>0.0]
使用iterrow()方法
for index, row in no_cost_prc.iterrows():
print(index)
sku_id = row['sku_id']
sku_sale_prc = row['sku_sale_prc']
temp = full_info_turnover[
(full_info_turnover['sku_id'] == sku_id) & (full_info_turnover['sku_sale_prc'] == sku_sale_prc)]
if temp.empty == False:
row['sku_cost_prc'] = temp['sku_cost_prc'].values[0]
else:
continue
使用Ndarray
sku_sale_prc_arr = full_info_turnover['sku_sale_prc'].values
sku_cost_prc_arr = full_info_turnover['sku_cost_prc'].values
sku_id_arr = full_info_turnover['sku_id'].values
non_sku_cost_arr = no_cost_prc['sku_cost_prc'].values
non_sku_sale_prc_arr = no_cost_prc['sku_sale_prc'].values
non_sku_id_arr = no_cost_prc['sku_id'].values
for i in range(non_sku_cost_arr.shape[0]):
print(i)
temp = sku_cost_prc_arr[np.where(sku_id_arr == non_sku_id_arr[i]) and np.where(sku_sale_prc_arr == non_sku_sale_prc_arr[i])]
if temp.size !=0:
non_sku_cost_arr[i] = temp[0]
else:
continue
使用Merge方法进行匹配
对于能匹配到的信息的商品用信息补全 没有匹配到的取利润率20%到40%间的一个随机数
no_cost_prc = no_cost_prc.drop_duplicates(keep='first')
Merged_info = pd.merge(no_cost_prc,full_info_turnover,how = "left",on = ['sku_id','sku_sale_prc'])
norepeat_df = Merged_info.drop_duplicates(subset=['sku_id','sku_sale_prc','create_dt_x','order_id_x','sku_name_x','is_finished_x','sku_cnt_x','sku_prc_x','sku_cost_prc_x','upc_code_x'], keep='first')
norepeat_df.index = np.arange(norepeat_df.shape[0])
no_cost_prc.index = np.arange(norepeat_df.shape[0])
norepeat_df.iloc[:,8] = norepeat_df.iloc[:,16]
norepeat_df['sku_cost_prc_x'] = norepeat_df['sku_cost_prc_x'].fillna(0)
norepeat_df_filled = norepeat_df[norepeat_df['sku_cost_prc_x'] !=0]
norepeat_df_to_fill = norepeat_df[norepeat_df['sku_cost_prc_x'] ==0]
norepeat_df_to_fill['sku_cost_prc_x'] = norepeat_df_to_fill.apply(lambda x:x['sku_sale_prc']/(random.uniform(0.2, 0.4)+1),axis=1)
norepeat_df_fullfilled = pd.concat([norepeat_df_to_fill,norepeat_df_filled])
norepeat_df_fullfilled = norepeat_df_fullfilled.iloc[:,:10]
ori_tags = ['create_dt','order_id','sku_id','sku_name','is_finished','sku_cnt','sku_prc','sku_sale_prc','sku_cost_prc','upc_code']
norepeat_df_fullfilled.columns=ori_tags
fullfiled_turnovers = pd.concat([norepeat_df_fullfilled,full_info_turnover])
fullfiled_turnovers.index = np.arange(fullfiled_turnovers.shape[0])
展示补全的表
fullfiled_turnovers
| create_dt | order_id | sku_id | sku_name | is_finished | sku_cnt | sku_prc | sku_sale_prc | sku_cost_prc | upc_code | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2016-11-30 | 628897900000121 | 2005508919 | 进口 香蕉 约1kg | 1 | 1 | 8.8 | 8.8 | 6.790909 | 2400002414566 |
| 1 | 2016-11-30 | 628897900000121 | 2004962651 | 伊利 畅轻风味发酵乳 燕麦+芒果味酸奶 250g | 1 | 1 | 7.5 | 7.5 | 5.365986 | 6907992103419 |
| 2 | 2016-12-02 | 629091200000042 | 2005508964 | 五花肉 约500g | 1 | 1 | 13.5 | 13.5 | 10.055045 | 2400002413040 |
| 3 | 2016-12-02 | 629091200000042 | 2005508949 | 青尖椒 约400g | 1 | 1 | 3.9 | 3.9 | 2.933400 | 2400002414306 |
| 4 | 2016-12-02 | 629091200000042 | 2005468473 | 天马 腐竹 180g | 1 | 1 | 10.8 | 10.8 | 8.702881 | 6922547652280 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1123427 | 2019-01-02 | 900150830000141 | 2009205131 | Richeese/丽芝士 印度尼西亚进口 纳宝帝奶酪威化饼干 350g | 1 | 1 | 19.9 | 19.8 | 19.800000 | 8.99318e+12 |
| 1123428 | 2019-01-02 | 900150830000141 | 2003621597 | 思念 宁波风味黑芝麻汤圆 1kg | 1 | 1 | 10.9 | 9.9 | 9.900000 | 6.92167e+12 |
| 1123429 | 2019-01-02 | 900150830000141 | 2006240781 | 巨龙 窝窝米酒+红糖米酒 828g(418g+410g) | 1 | 1 | 11.8 | 9.9 | 9.900000 | 6.92412e+12 |
| 1123430 | 2019-01-02 | 900152711000122 | 2011596565 | 海天 上等蚝油组合装 520g*2瓶(新旧包装,随机发货) | 1 | 1 | 15.0 | 9.9 | 9.900000 | 6.90227e+12 |
| 1123431 | 2019-01-02 | 900152711000122 | 2006613346 | 黄瓜山 鲜鸡蛋 10枚?400g | 1 | 1 | 10.9 | 9.9 | 9.900000 | 6.95612e+12 |
1123432 rows × 10 columns
Q1 计算该商场从2016年11月30日到2019年1月2日每天的营业额和利润率
Q1_start_time = np.datetime64('2016-11-30')
Q1_end_time = np.datetime64('2019-01-02')
fullfiled_turnovers['create_dt'] = fullfiled_turnovers['create_dt'].astype('datetime64')
Sales_dic = {}
Ori_sales = {}
Profit_rate_dic = {}
flag = 0
def process_sheet(Q1_start_time):
time_revised_sheet_1 = fullfiled_turnovers[(fullfiled_turnovers['create_dt']==Q1_start_time)]
Q1_sheet = time_revised_sheet_1[['sku_cnt','sku_prc','sku_sale_prc','sku_cost_prc','upc_code']]
Q1_sheet['upc_code'] = Q1_sheet.apply(lambda x:x['sku_cnt']*x['sku_sale_prc'],axis=1)
Q1_sales = Q1_sheet['upc_code'].sum()
Q1_sheet = time_revised_sheet_1[['sku_cnt','sku_prc','sku_sale_prc','sku_cost_prc','upc_code']]
Q1_sheet['upc_code'] = Q1_sheet.apply(lambda x:x['sku_cnt']*x['sku_cost_prc'],axis=1)
Q1_costs = Q1_sheet['upc_code'].sum()
Q1_profit_rate = (Q1_sales - Q1_costs)/Q1_costs
Q1_sheet = time_revised_sheet_1[['sku_cnt','sku_prc','sku_sale_prc','sku_cost_prc','upc_code']]
Q1_sheet['upc_code'] = Q1_sheet.apply(lambda x:x['sku_cnt']*x['sku_prc'],axis=1)
Q1_ori_sales = Q1_sheet['upc_code'].sum()
return Q1_profit_rate,Q1_sales,Q1_costs,Q1_ori_sales
while Q1_start_time<=Q1_end_time:
if (fullfiled_turnovers[(fullfiled_turnovers['create_dt']==Q1_start_time)].empty):
Sales_dic[flag] = [Q1_start_time,0]
Profit_rate_dic[flag] = [Q1_start_time,0]
Q1_start_time = Q1_start_time + 1
continue
if not(fullfiled_turnovers[(fullfiled_turnovers['create_dt']==Q1_start_time)].empty):
Q1_profit_rate,Q1_sales,Q1_costs,Q1_ori_sales = process_sheet(Q1_start_time)
Sales_dic[flag] = [Q1_start_time,Q1_sales]
Profit_rate_dic[flag] = [Q1_start_time,Q1_profit_rate]
Ori_sales[flag] = [Q1_start_time,Q1_ori_sales]
Q1_start_time = Q1_start_time + 1
flag += 1
Q2 选取合适的指标衡量商场每天的打折力度,并计算2016年11月30日到2019年1月2日每天的打折力度
用每天的标价和售价的差再除以标价来定义打折力度
Before 2017年3月7日
Profit_rate = pd.DataFrame(Profit_rate_dic).T
Profit_rate.columns = ['date','profit_rate']
Discont_rate_dic = {}
Ori_sales_pd = pd.DataFrame(Ori_sales).T
Ori_sales_pd.columns = ['date','ori_sales']
Sales = pd.DataFrame(Sales_dic).T
Sales.columns = ['date','sale']
Q2_final_sheet = pd.merge(Ori_sales_pd,Sales,on=['date'])
Q2_final_sheet['discount_rate'] = ''
Q2_final_sheet_ = pd.merge(Q2_final_sheet,Profit_rate,on=['date'])
Q2_final_sheet_['discount_rate'] = Q2_final_sheet.apply(lambda x:(x['ori_sales']-x['sale'])/x['ori_sales'],axis=1)
Q2_final_sheet_
| date | ori_sales | sale | discount_rate | profit_rate | |
|---|---|---|---|---|---|
| 0 | 2016-11-30 | 3306.3 | 2833.7 | 0.142939 | 0.0856733 |
| 1 | 2016-12-01 | 2564 | 2346.2 | 0.084945 | 0.143429 |
| 2 | 2016-12-02 | 2594.9 | 2338.3 | 0.098886 | 0.123242 |
| 3 | 2016-12-03 | 3692.6 | 3270.4 | 0.114337 | 0.119463 |
| 4 | 2016-12-04 | 4319.18 | 3881.68 | 0.101292 | 0.11417 |
| ... | ... | ... | ... | ... | ... |
| 758 | 2018-12-29 | 68383.4 | 60221.9 | 0.119349 | 0.108456 |
| 759 | 2018-12-30 | 172531 | 150242 | 0.129189 | 0.136967 |
| 760 | 2018-12-31 | 157145 | 138077 | 0.121343 | 0.146125 |
| 761 | 2019-01-01 | 73650.9 | 65018 | 0.117214 | 0.0982922 |
| 762 | 2019-01-02 | 35702.4 | 31072.6 | 0.129678 | 0.0993041 |
763 rows × 5 columns
Q3分析打折力度与商品销售额以及利润率的关系
x = np.arange(0,len(Sales_dic))
fig = plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(x,Q2_final_sheet_['sale'].values,'r')
ax.set_title('Sales per Day')
ax.set_xticks([0,760])
ax.set_xticklabels(['2016-11-30','2019-1-2'],fontsize= 'small')
plt.savefig('4.jpg')
plt.show()
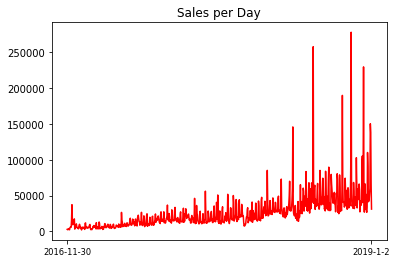
上图为销售额画图
fig = plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(x,Q2_final_sheet_['profit_rate'].values)
ax.set_title('Profit rate per Day')
ax.set_xticks([0,760])
ax.set_xticklabels(['2016-11-30','2019-1-2'],fontsize= 'small')
plt.savefig('4.jpg')
plt.show()
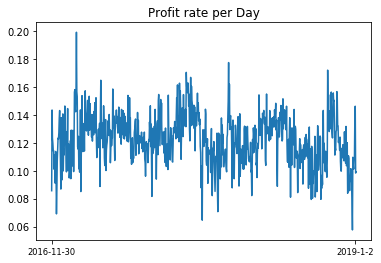
x = np.arange(0,len(Profit_rate_dic))
fig = plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(x,Q2_final_sheet_['discount_rate'],'r')
ax.set_title('Discount value per Day')
ax.set_xticks([0,760])
ax.set_xticklabels(['2016-11-30','2019-1-2'],fontsize='small')
plt.savefig('4.jpg')
plt.show()
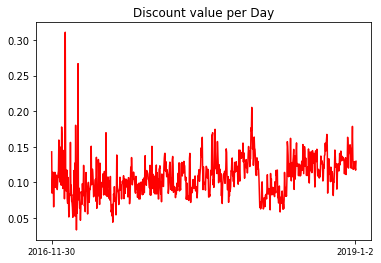
上图为打折力度
Q2_final_sheet_['profit_rate'] = Q2_final_sheet_['profit_rate'].astype('float')
Q2_final_sheet_['sale'] = Q2_final_sheet_['sale'].astype('float')
Q2_final_sheet_['ori_sales'] = Q2_final_sheet_['ori_sales'].astype('float')
Q2_final_sheet_.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 763 entries, 0 to 762
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 date 763 non-null datetime64[ns]
1 ori_sales 763 non-null float64
2 sale 763 non-null float64
3 discount_rate 763 non-null float64
4 profit_rate 763 non-null float64
dtypes: datetime64[ns](1), float64(4)
memory usage: 35.8 KB
Q2_final_sheet_.corr()
| ori_sales | sale | discount_rate | profit_rate | |
|---|---|---|---|---|
| ori_sales | 1.000000 | 0.999409 | 0.391121 | -0.342592 |
| sale | 0.999409 | 1.000000 | 0.371427 | -0.329258 |
| discount_rate | 0.391121 | 0.371427 | 1.000000 | -0.555441 |
| profit_rate | -0.342592 | -0.329258 | -0.555441 | 1.000000 |
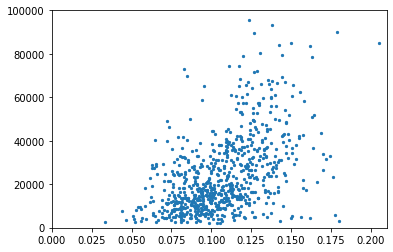
打折力度和销售额
x = Q2_final_sheet_['discount_rate'].values.reshape(-1, 1)
y = Q2_final_sheet_['sale'].values.reshape(-1, 1)
plt.xlim(-0,0.21)
plt.ylim(-100,100000)
plt.scatter(x, y,s=5)
plt.show()
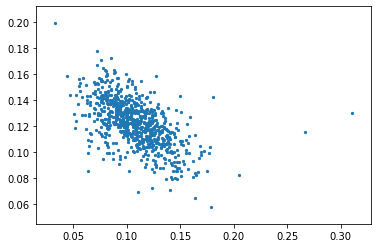
打折力度和利润率
x = Q2_final_sheet_['discount_rate'].values.reshape(-1, 1)
y = Q2_final_sheet_['profit_rate'].values.reshape(-1, 1)
plt.scatter(x, y,s=5)
plt.show()
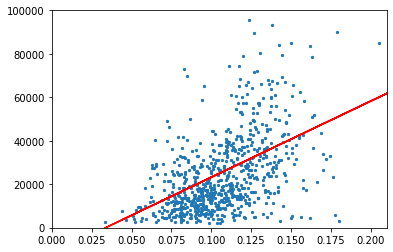
打折力度和销售额的关系
from sklearn.linear_model import LinearRegression
linreg = LinearRegression()
linreg.fit(Q2_final_sheet_['discount_rate'].values.reshape(-1, 1), Q2_final_sheet_['sale'].values.reshape(-1, 1))
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
线性回归系数
linreg.intercept_
array([-11890.35672382])
linreg.coef_
array([[350536.31765171]])
x = Q2_final_sheet_['discount_rate'].values.reshape(-1, 1)
y = Q2_final_sheet_['sale'].values.reshape(-1, 1)
x_ = Q2_final_sheet_['sale'].sum()/Q2_final_sheet_.shape[0]
x_
re_sq = Q2_final_sheet_['sale'] - x_
re_sq = re_sq.apply(lambda x:x*x).sum()
yr = linreg.predict(x)
res = np.mean((linreg.predict(x) - y) ** 2)
R_square = 1- res/re_sq
R_square
0.9988701937555191
res
543409378.8085167
re_sq
480975726115.033
x = Q2_final_sheet_['discount_rate'].values.reshape(-1, 1)
y = Q2_final_sheet_['sale'].values.reshape(-1, 1)
plt.xlim(-0,0.21)
plt.ylim(-100,100000)
Y = yr
plt.scatter(x, y,s=5)
plt.plot(x,Y,'r-')
plt.show()
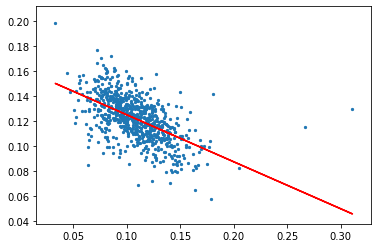
打折力度和利润率的关系
x = Q2_final_sheet_['discount_rate'].values.reshape(-1, 1)
y = Q2_final_sheet_['profit_rate'].values.reshape(-1, 1)
linreg_ = LinearRegression()
linreg_.fit(x,y)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
计算出的系数
linreg_.intercept_
array([0.16283051])
linreg_.coef_
array([[-0.37723069]])
yr_ = linreg_.predict(x)
plt.scatter(x, y,s=5)
plt.plot(x,yr_,'r-')
plt.show()
```python x_ = Q2final_sheet[‘discount_rate’].sum()/Q2final_sheet.shape[0]
x_
re_sq = Q2final_sheet[‘discount_rate’] - x_
re_sq = re_sq.apply(lambda x:x*x).sum()
yr_ = linreg_.predict(x)
res = np.mean((linreg_.predict(x) - y) ** 2)
R_square = 1- res/re_sq