This is my learning procedure of the Kaggle competition-Titanic: Machine Learning From Disaster, this problem serves as the very first attemp for most of the rookie in Kaggle.Without further ado,let’s get started. This post follows the steps of the Alexis Cook‘s Titanic Tutorial.
1.Get started
The challenge
The competition is simple:use the Titanic passenger data to try to predict who will survive and who will die.
The data
Data is crucial for data science.Let’s have a look.The data has split into two groups:training set(train.csv) and test set(test.csv)
Data Dictionary
| Variable | Definition | Key |
|---|---|---|
| survival | Surviaval | 0 = No, 1 = Yes |
| pclass | Ticket class | 1 = 1st, 2 = 2nd, 3 = 3rd |
| sex | Sex | |
| Age | Age in years | |
| sibsp | # of siblings / spouses aboard the Titanic | |
| parch | # of parents / children aboard the Titanic | |
| ticket | Ticket number | |
| fare | Passenger fare | |
| cabin | Cabin number | |
| embarked | Port of Embarkation | C = Cherbourg, Q = Queenstown, S = Southampton |
Variable Notes
pclass: A proxy for socio-economic status (SES)
1st = Upper
2nd = Middle
3rd = Lower
age: Age is fractional if less than 1. If the age is estimated, is it in the form of xx.5
sibsp: The dataset defines family relations in this way…
Sibling = brother, sister, stepbrother, stepsister
Spouse = husband, wife (mistresses and fiancés were ignored)
parch: The dataset defines family relations in this way…
Parent = mother, father
Child = daughter, son, stepdaughter, stepson
Some children travelled only with a nanny, therefore parch=0 for them.
(1).train.csv
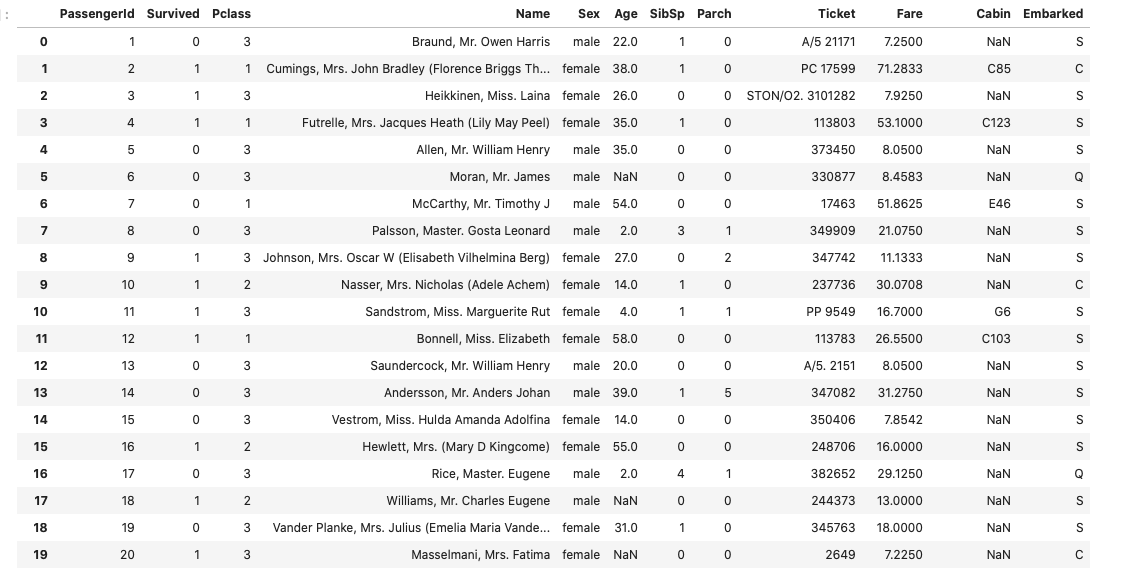
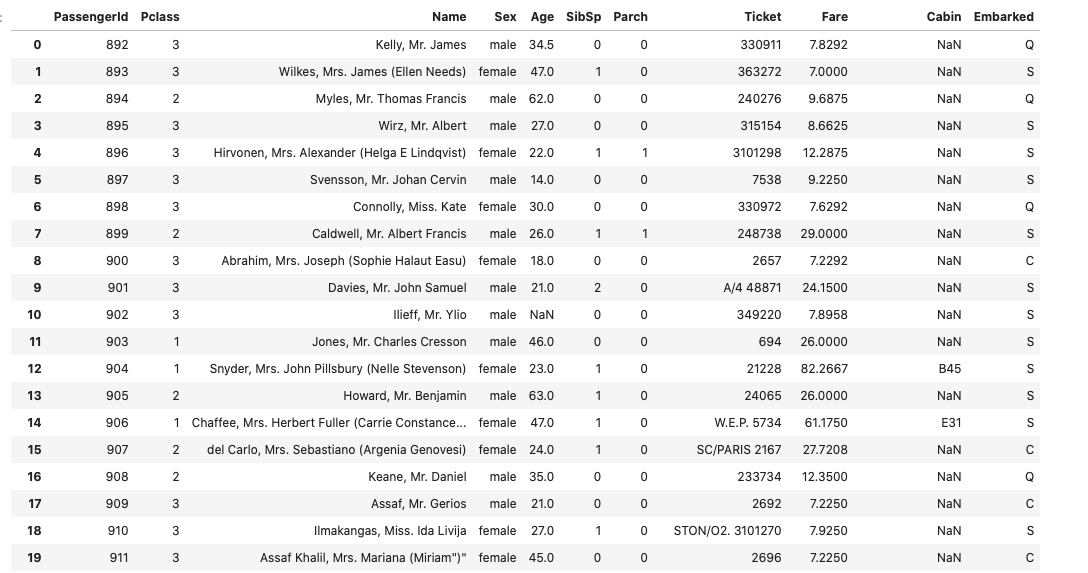
(2).test.csv
2.Show me the code
I choose Python as my programming language to handle data problems. Although the R language is efficient too, for me, I still love Python. I copy the introduction of pandas library from its official website.
pandas is an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language.
pandas is a NumFOCUS sponsored project. This will help ensure the success of development of pandas as a world-class open-source project, and makes it possible to donate to the project.
Load the data
The loading procedure is simple.
the location of the csv files depends on the distribution of the files in your system
import pandas as pd
train_data = pd.read_csv('data/train.csv')
test_data = pd.read_csv('data/test.csv')
···